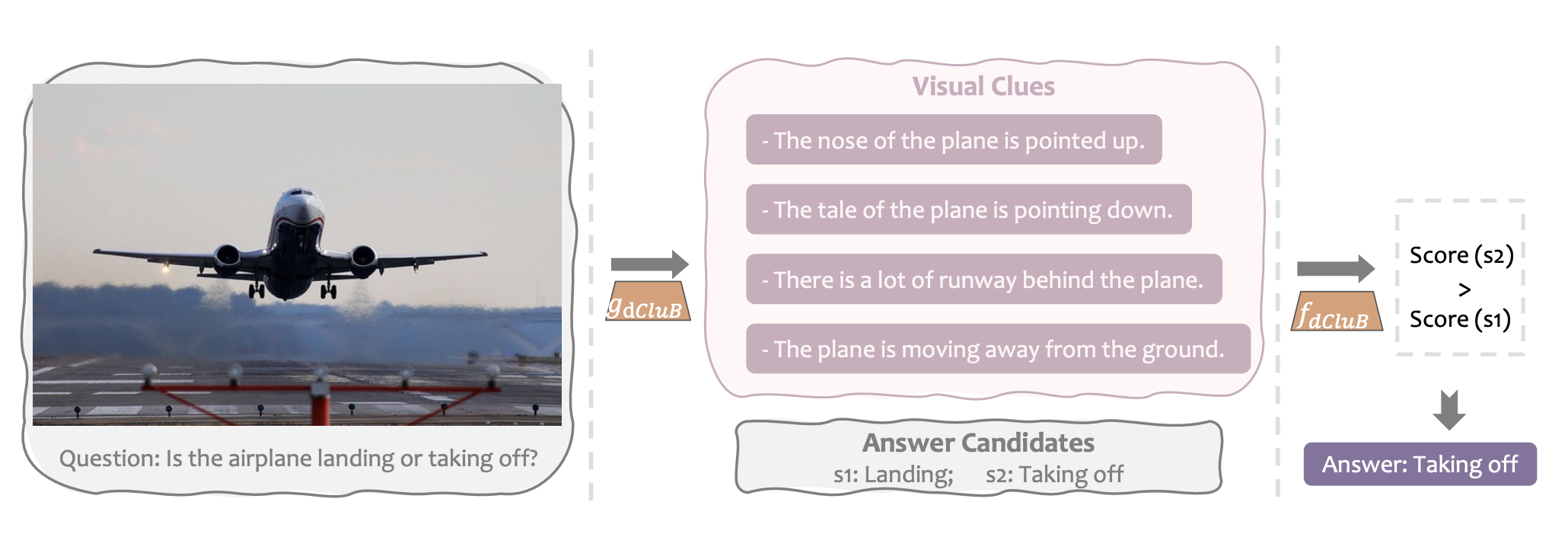
Xingyu Fu (府星妤)
👋 I am a Postdoctoral Fellow at Princeton University's PLI, working with Zhuang Liu, Danqi Chen, and Sanjeev Arora.
My research primarily focuses on generative multimodal models at the intersection between vision and natural language (e.g., multimodal LLMs, text-to-image/video generation, omni models). I aim to improve the perception and reasoning capabilities of multimodal models by bridging them together. I have built better evaluations for emergent abilities, and used synthetic data to design models that can better perceive and reason about the multimodal world. My PhD thesis is Bridging Perception and Reasoning in Multimodal Models.
I earned my Ph.D. in Computer Science at the University of Pennsylvania advised by Prof. Dan Roth from 2020 to 2025. During my PhD, I interned at Microsoft and AWS AI Labs. I did my B.S. in Computer Science at UIUC from 2017 to 2020, where I was very fortunate to be advised by Prof. Jiawei Han and Prof. Jingbo Shang.